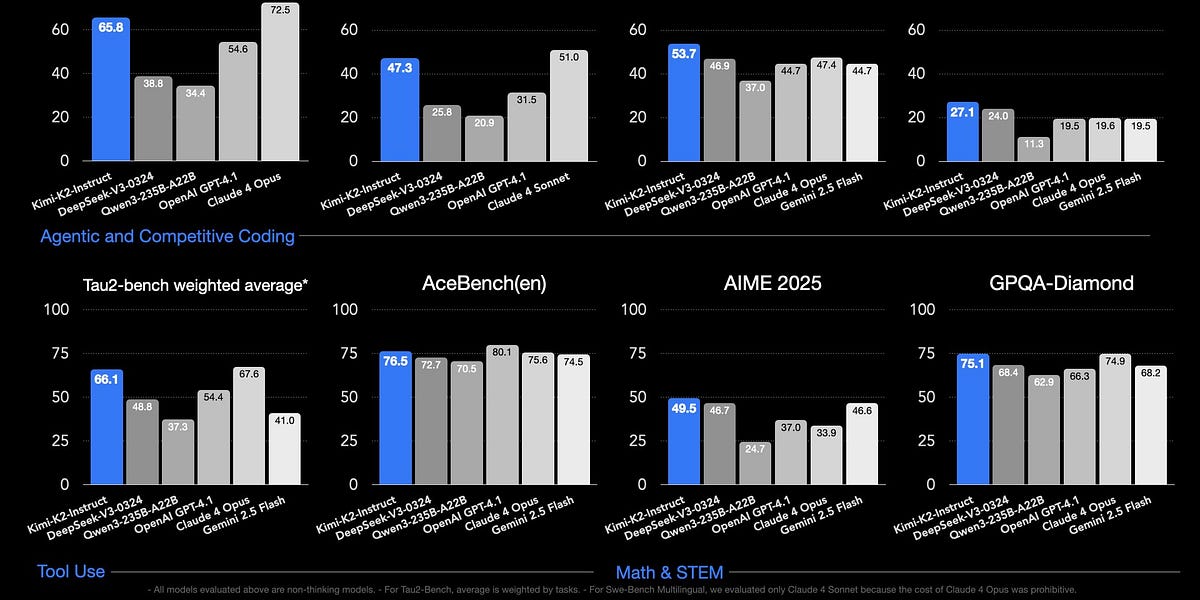
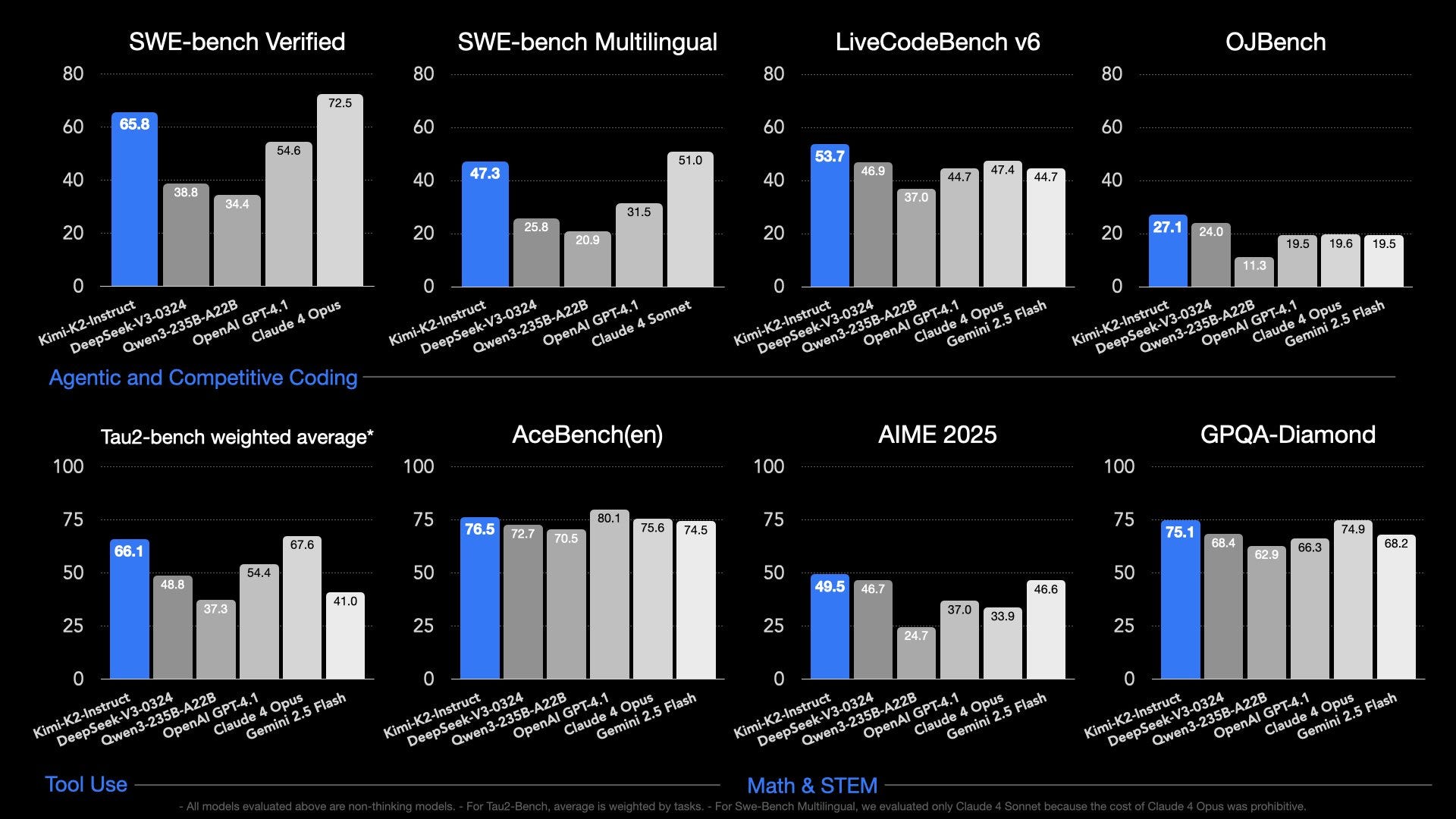
AI experts return from China stunned: The US grid is so weak, the race may already be over
By
Eva Roytburg
Fellow, News
August 14, 2025 at 3:55 PM EDT
A drone photo shows staff members of State Grid Bortala Electric Power Supply Company patrolling near Sayram Lake scenic area to ensure power supply in Bortala Mongolian Autonomous Prefecture, northwest China's Xinjiang Uygur Autonomous Region, July 17, 2025.
Yin Tianjie/Xinhua via Getty Images
“Everywhere we went, people treated energy availability as a given,” Rui Ma
wrote on
X after returning from a recent tour of China’s AI hubs.
For American AI researchers, that’s almost unimaginable. In the U.S.,
surging AI demand is colliding with a fragile power grid, the kind of extreme bottleneck that Goldman Sachs
warns could severely choke the industry’s growth.
In China, Ma continued, it’s considered a “solved problem.”
Ma, a renowned expert in Chinese technology and founder of the media company
Tech Buzz China, took her team on the road to get a firsthand look at the country’s AI advancements. She told
Fortune that while she isn’t an energy expert, she attended enough meetings and talked to enough insiders to come away with a conclusion that should send chills down the spine of Silicon Valley: in China, building enough power for data centers is no longer up for debate.
“This is a stark contrast to the U.S., where AI growth is increasingly tied to debates over data center power consumption and grid limitations,” she wrote on X.
The stakes are difficult to overstate. Data center building is the foundation of AI advancement, and spending on new centers
now displaces consumer spending in terms of impact to U.S. GDP—that’s concerning since consumer spending is generally two-thirds of the pie.
McKinsey projects that between 2025 and 2030, companies worldwide will need to
invest $6.7 trillion into new data center capacity to keep up with AI’s strain.
In a
recent research note, Stifel Nicolaus warned of a looming correction to the S&P 500, since it forecasts this data-center capex boom to be a one-off build-out of infrastructure, while consumer spending is clearly on the wane.
However, the clear limiting factor to the U.S.’s data center infrastructure development, according to a
Deloitte industry survey, is stress on the power grid. Cities’ power grids are
so weak that some companies are just
building their own power plants rather than relying on existing grids. The public is growing increasingly frustrated over
increasing energy bills – in Ohio, the electricity bill for a typical household has increased at least $15 this summer from the data centers – while energy companies prepare for a sea-change of surging demand.
Goldman Sachs
frames the crisis simply: “AI’s insatiable power demand is outpacing the grid’s decade-long development cycles, creating a critical bottleneck.”
Meanwhile, David Fishman, a Chinese electricity expert who has spent years tracking their energy development, told
Fortune that in China, electricity isn’t even a question. On average, China adds more electricity demand than the entire annual consumption of Germany, every single year. Whole rural provinces are blanketed in rooftop solar, with one province matching the entirety of India’s electricity supply.
“U.S. policymakers should be hoping China stays a competitor and not an aggressor,” Fishman said. “Because right now they can’t compete effectively on the energy infrastructure front.”
China has an oversupply of electricty
China’s quiet electricity dominance, Fishman explained, is the result of decades of deliberate overbuilding and investment in every layer of the power sector, from generation to transmission to next-generation nuclear.
The country’s reserve margin has never dipped below 80%–100% nationwide, meaning it has consistently maintained at least twice the capacity it needs, Fishman said. They have so much available space that instead of seeing AI data centers as a threat to grid stability, China treats them as a convenient way to “soak up oversupply,” he added.
That level of cushion is unthinkable in the United States, where regional grids typically operate with a 15% reserve margin and sometimes less, particularly during extreme weather, Fishman said. In places like California or Texas, officials often issue
warnings about red-flag
conditions when demand is projected to strain the system. This leaves little room to absorb the rapid load increases AI infrastructure requires, Fishman ntoed.
The gap in readiness is stark: while the U.S. is already experiencing political and economic
fights over whether the grid can keep up, China is operating from a position of abundance.
Even if AI demand in China grows so quickly renewable projects can’t keep pace, Fishman said, the country can tap idle coal plants to bridge the gap while building more sustainable sources. “It’s not preferable,” he admitted, “but it’s doable.”
By contrast, the U.S. would have to
scramble to bring on new generation capacity, often facing years-long permitting delays, local opposition, and fragmented market rules, he said.
Structural governance differences
Underpinning the hardware advantage is a difference in governance. In China, energy planning is coordinated by long-term, technocratic policy that defines the market’s rules before investments are made, Fishman said. This model ensures infrastructure buildout happens in anticipation of demand, not in reaction to it.
“They’re set up to hit grand slams,” Fishman noted. “The U.S., at best, can get on base.”
In the U.S., large-scale infrastructure projects depend heavily on private investment, but most investors expect a return within three to five years: far too short for power projects that can take a decade to build and pay off.
“Capital is really biased toward shorter-term returns,” he said, noting Silicon Valley has funneled billions into “the nth iteration of software-as-a-service” while energy projects fight for funding.
In China, by contrast, the state directs money toward strategic sectors in advance of demand, accepting not every project will succeed but ensuring the capacity is in place when it’s needed. Without public financing to de-risk long-term bets, he argued, the U.S. political and economic system is simply not set up to build the grid of the future.
Cultural attitudes reinforce this approach. In China, renewables are framed as a cornerstone of the economy because they make sense economically and strategically, not because they carry moral weight. Coal use isn’t cast as a sign of villainy, as it would be among some circles in the U.S. – it’s simply seen as outdated. This pragmatic framing, Fishman argued, allows policymakers to focus on efficiency and results rather than political battles.
For Fishman, the takeaway is blunt. Without a dramatic shift in how the U.S. builds and funds its energy infrastructure, China’s lead will only widen.
“The gap in capability is only going to continue to become more obvious — and grow in the coming years,” he said.